マルチコアで高速化処理を実現するための手法:組み込みマルチコア進化論(3)(1/3 ページ)
for文やwhile文などの繰り返し処理を並列化することで、マルチコア処理の高速化、ホットスポットの高速化を図る!
はじめに
前回は、マルチコア分割(並列化)手法を読者の皆さんと進化させていくというテーマで、「並列化を検討する際の有効ポイント」を紹介しました。今回は、並列化を行う高速化手法の中で最も一般的な、繰り返し処理におけるデータの並列化手法を紹介します。
この手法は、繰り返し行われるfor文やwhile文などの処理(ループ構文)に着目し、その処理を並列に動作させることで、高速化を図ります。繰り返し処理に着目することで並列化する部分が明確になりますので、高速化のための並列化検討において、最初に考えるべきポイントとなります。
また、繰り返し処理は処理時間がかかっていることも多いため、並列化することで、ホットスポットの高速化も期待されます。よって全体のスループット向上が期待されることはいうまでもありません。
繰り返し処理の並列化
本連載の第1回でもマルチコア環境並列化手法の分類を簡単に説明しましたが、下表の赤枠内が、繰り返し処理の並列化に関する部分であり、今回説明する部分です。
繰り返し処理内で使用している外部変数や内部変数に依存関係が存在しない場合に、1つのタスク内を分割することで、繰り返し処理を並列化します。
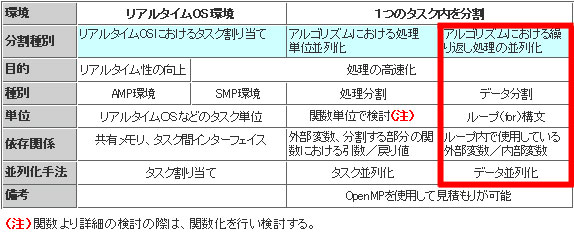 表 マルチコア環境並列化手法の分類
表 マルチコア環境並列化手法の分類分割を検討する
例えば、for( cnt = 0; cnt < 16; cnt++ ){…}という繰り返し処理では、{…}内の処理が16回繰り返されますが、それを4分割する場合、1つ目をcnt0〜3の処理、2つ目をcnt4〜7の処理、3つ目をcnt8〜11の処理、4つ目をcnt12〜15の処理に分けます。
int cnt;
for( cnt = 0; cnt < 16; cnt++ ){
. . . //繰り返し処理
}
上記のプログラムを4つの処理に分割すると、以下のようになります。関数がコールされる場所に着目しましょう。
★分割1
int cnt;
for( cnt = 0; cnt < 4; cnt++ ){
. . . //繰り返し処理
}
★分割2
int cnt;
for( cnt = 4; cnt < 8; cnt++ ){
. . . //繰り返し処理
}
★分割3
int cnt;
for( cnt = 9; cnt < 12; cnt++ ){
. . . //繰り返し処理
}
★分割4
int cnt;
for( cnt = 12; cnt < 16; cnt++ ){
. . . //繰り返し処理
}
依存関係を考慮する
分割した各繰り返し処理で共通に使用している外部変数や内部変数がある場合、データレーシング(計算結果が違ってしまう)などの問題を検討する必要があります。逐次処理で決まった順序に実行する場合はいいですが、並列に実行する場合には、実行順序が変更したときに、そうした依存関係が起きてしまいます。
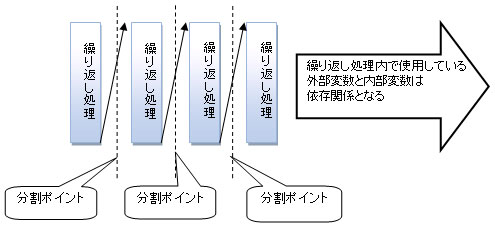 図1 並列型分割手法
図1 並列型分割手法データ並列化
逐次処理を並列処理に変更する手法には「データ並列化」「パイプライン並列化」「タスク並列化」の3通りがあります。
データ並列化は、繰り返し単位での分割を検討する際に有効な手法です。まず、データ分割を行い、その分割したデータをそれぞれの各コアに割り当てて並列に処理することで高速化を図ります。
例えば、8個のデータが存在したとします(図2を参照してください)。シングルコアの場合は、1つ目のデータ(1)から8つ目のデータ(8)までが順番に実行されます。つまり、データ8個分の処理時間がかかります。しかし、コアが4つ存在する場合には、1つ目のコアが(1)と(2)のデータの処理を行い、2つ目のコアが(3)と(4)の処理を、3つ目のコアが(5)と(6)の処理を、そして、4つ目のコアが(7)と(8)のデータ処理を行います。各コアは並列に動作されるため、データ2個分の処理時間ですべての処理を終了します。
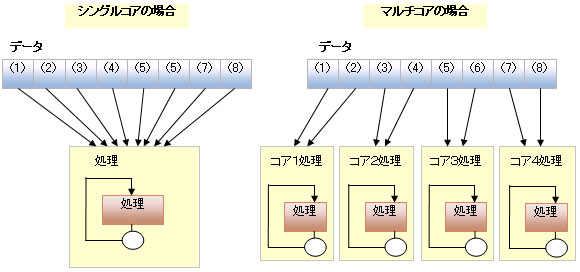 図2 データ並列化を行った際のシングルコアとマルチコアの比較
図2 データ並列化を行った際のシングルコアとマルチコアの比較Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- 5G通信の遅延時間1ms以下は複数端末の制御でも可能か、東芝が量子技術で道を開く
- CAN通信におけるデータ送信の仕組みとは?
- イチから全部作ってみよう(7)正しい要求仕様書の第一歩となるヒアリングの手順
- CANプロトコルを理解するための基礎知識
- 組み込みシステム向けRTOSのシェアはTRON系が約60%
- ソニーのLPWA「ELTRES」の通信モジュールが機能追加、システムの簡素化が可能に
- インフィニオンのSiC-MOSFETは第2世代へ、質も量も圧倒
- 【問題7】10進数を2進数に変換するプログラム
- テスト消化曲線とバグ発生曲線の7パターン診断
- 6Gに向けたサブテラヘルツ帯対応無線デバイス、100Gbpsの超高速伝送を実証
よく読まれている編集記者コラム



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。