
プロセスの微細化で何が変わるのか!? 28nm FPGAが与えるインパクト:FPGA Watch(7)(1/2 ページ)
「最先端技術は、一部の市場やアプリケーション向けのものであって、自分にはまだまだ関係のないもの」「最新のFPGAを使いこなすには、特別な知識やスキルが必要で、自分には荷が重いのではないか」などと思ってはいないでしょうか。今回は、“28nm FPGA”で何が変わるのか、どのような利点をもたらしてくれるのかについて紹介します。
はじめに
2010年にアルテラ社とザイリンクス社の両社がそれぞれ発表していた28nm世代のFPGAの出荷が今春(2011年)から始まりました。皆さんは「28nm FPGA」と聞いて、どのような印象をお持ちでしょうか。
「最先端技術は、一部の市場やアプリケーション向けのものであって、自分にはまだまだ関係のないもの」と感じているでしょうか。あるいは、「最新のFPGAを使いこなすには、特別な知識やスキルが必要で、自分には荷が重いのではないか」と思ってはいないでしょうか。
今回は、“28nm FPGA”で何が変わるのか、どのような利点をもたらしてくれるのかについて紹介したいと思います。
そもそも「28nm」とは何?
“28nm”という数字は、半導体集積回路において「プロセスノード」と呼ばれる、デバイスの特定部分の寸法を表しています。ロジック半導体デバイスでは、一般的にトランジスタ(MOSFET:金属酸化膜電界効果トランジスタ)のゲート配線の“幅”、または“間隔”を指します。この寸法を小さくすることを半導体プロセスの「微細化」といい、微細化に伴って製造上の技術的な高度さや困難さが増していきます。
現在のロジック半導体(プロセッサやASIC)におけるプロセスルールは、「ハーフピッチ」と呼ばれる寸法で、ゲートの線幅の中心から線間の中心までの距離で表すことが一般的になっています。
ロジック半導体の微細化は、おおよそ、以下のような歴史で進んできました(表1)。
| 1980年代 | 5um、3um、2um、1.5um、1.2um/1.0um、0.8um |
|---|---|
| 1990年代 | 0.65um、0.5um、0.35um、0.25um |
| 1999年/2000年 | 180nm |
| 2001年/2002年 | 130nm |
| 2004年 | 90nm |
| 2006年 | 65nm/60nm |
| 2008年 | 45nm/40nm |
| 2010年 | 32nm/28nm |
| 表1 ロジック半導体の微細化の歴史 | |
このように、約2年ごとに次世代のプロセス技術に微細化されています。ここに示す時期は製品に適用された年であり、インテル社のプロセッサが代表的な例ですが、2000年以降のFPGAもほぼこれと同じ歴史をたどってきています。
プロセス微細化をけん引する半導体製品は何か?
プロセスの微細化は、かつて、DRAMが推進してきました。ロジック系デバイスの推進者は、やはり汎用(PC用)プロセッサチップであり、さらに2000年代以降はグラフィックスチップが先端プロセスを第1に採用しています。カスタムLSIデバイス(ASIC)は、2000年代前半まで先端プロセスを追い求めてきましたが、ゲーム機向けなどの一部の用途を除くと、一般に多く採用されているプロセス技術は130~90nmであり、これはこの10年ほど変わっていません。
一方、FPGAの場合は上記のプロセス技術ロードマップに沿って製品化されてきました。FPGAは、今や汎用プロセッサや先端グラフィックスチップと並び・凌ぐほどのペースで先端プロセスを用いて製品化しているといえます。
アルテラ社の試算では、130nmプロセスによるセルベースASICと40nmプロセスのFPGAでは、同じ条件のロジックを実装した場合、ほぼ同じ程度のチップ面積になるとしています。もちろん、実際の設計はピュアなロジック回路だけではありませんが、ユーザーの立場としては、開発コストの点から微細化を進められないASICに比べて、最先端のプロセスを用いたデバイスを早期に使用できるFPGAは、今後も継続して期待できるカスタムロジックデバイスであることを理解する良い例だと思います。
――そして、今(今春から)、28nm世代のFPGA製品を使用できるようになったのです。
なぜ“最先端プロセス”が必要なのか?
プロセスの微細化の利点は、
- 集積度を高める(より多くの機能を統合する、または同じ機能を低コストで実現する)
- 動作性能を高める
- 消費電力を低くする
の3点にあります。
FPGAは、40nmや28nmに微細化を進めることにより、130nmや90nmのASICと競合できるパフォーマンスを手に入れてきたといえるでしょう。ASICは、ユーザー設計・要求ごとにカスタマイズ(最適化、チューニング)できるので、優位性を維持できる余地がまったくないということはないでしょうが、経済的(主に開発コスト)な課題や、設計バグや仕様変更への対応、あるいは開発期間(市場投入)などのリスクは、ますます増大しているといっていいでしょう。
また、最先端プロセス、かつ最新の市場動向を見据えて開発されたFPGA製品の多くは、最新のシリアルプロトコルやメモリインタフェースを標準的にサポートしています。例えば(アルテラ社の例)、メモリインタフェースはDDR3の場合、Stratix Vで最大1067MHz、Arria Vで最大667MHz、Cyclone Vで最大400MHzとなります。また、DDR2もサポートされているほか、ArriaやCycloneではLPDDR2やMobile DDRなど低消費電力向けのメモリもサポートされています。新しいプロセスのASICは開発費が膨大ですし、古いプロセスのASICでは技術的に実現が困難なのではないでしょうか。
このように、新しい規格に対応する場合でも、ユーザー側が少ない労力(工数)で最新の市場要求に応えるシステムを開発することができます。ユーザーが自身のシステム(製品)を市場で優位にするために、最先端プロセスを用いたFPGAは不可欠となっていくでしょう。
| 関連記事: | |
|---|---|
| ⇒ | ASICとFPGAの対比で見る“転換点”(2ページ目) |
“28nmプロセス”のFPGAは何が違うか?
28nmプロセス世代で、複数のFPGA製品ファミリが発表されています。先行しているアルテラ社とザイリンクス社は、ともにTSMC(Taiwan Semiconductor Manufacturing Corp.)社の技術を用いて製造しています。同じファウンドリの、同じ世代のプロセスを用いているのですが、実はTSMC社の28nmプロセスは1種類ではなく、現在公表されているものでは、「LP」「HP」「HPL」「HPM」の4種類があります。
LP(Low Power)プロセスは、最小のスタティック消費電力となるプロセス、HP(High Performance)は最高性能を発揮するためのプロセス、HPLはHPプロセスをベースにスタティック消費電力を低減して性能とのトレードオフを取ったプロセス、HPMはHPよりも性能を向上しつつLPと同等のスタティック消費電力を達成するプロセスとして位置付けられています。
| 関連リンク: | |
|---|---|
| ⇒ | TSMC社のWebサイト |
ザイリンクス社は、28nm世代の3ファミリ(Artix-7、Kintex-7、Virtex-7)に共通してHPLプロセスを用いています。一方、アルテラ社は、LPプロセスをCyclone V、Arria Vに、またHPプロセスをStratix Vに採用しています。もちろん、デバイスの特性は使用するプロセス技術だけで一義的に決まるものではなく、トランジスタ特性をどうするか、論理回路ブロックや配線のアーキテクチャ、リソースをどのように配分するかなど、さまざまな要素によって異なったものになります。
28nm FPGAがもたらすもの
プロセスの微細化(28nm FPGA)により、より多くの回路を搭載きるようになりました。そして、これにより、「コスト」「性能」「消費電力」のトレードオフの考え方にも変化が生じてきました。
例えば、消費電力を最小化することを目的としたプロセス技術を選択すると、従来の製品からの回路シュリンク(新しいプロセス技術に従来回路を移植)のやり方では、性能を妥協する必要があります。そこで、プロセス微細化による大きな集積度の向上を積極的に利用して、単位回路ブロックをより多機能・高機能にして、性能を改善することが重要となります。
アルテラ社の製品を例にとって紹介すると、28nm LP(Low Power)プロセスを用いるArria VとCyclone Vに対して、従来はハイエンド製品のStratixのみに搭載していたようなロジックブロック(ALM:Adaptive Logic Module)や、可変精度のDSPブロックを搭載しています。このような新しいアーキテクチャの適用により、LPプロセスを用いながら、さらに性能上の利点も得られるように工夫されています(図1)(図2)。
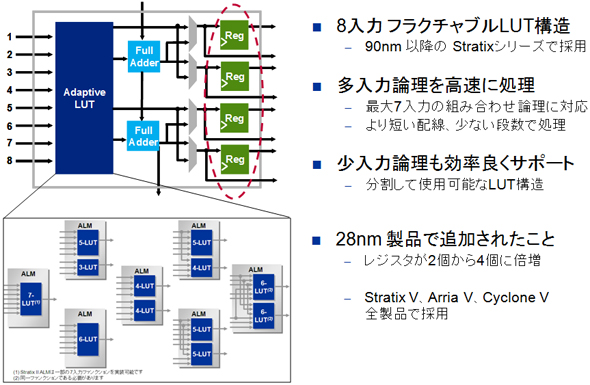 図1 進化したアーキテクチャの例(アルテラ社のAdaptive Logic Module)
図1 進化したアーキテクチャの例(アルテラ社のAdaptive Logic Module)
このように、微細化とアーキテクチャの進歩により、1つのダイ(チップ)に実装できるユーザー回路もますます大規模化が可能になっていきます。Stratix Vでは、ロジックブロックのAdvanced ALMの部分だけで100万個のロジックエレメント(LE:Logic Element)相当のロジックが実装できます。ASICゲート換算で1000万ゲート相当あり、これに加えてDSPブロックを利用することができます。
コネクティビティに関しては、ハイエンドの40G/100G光伝送アプリケーションから、Fibre ChannelやSATA、汎用的なPCI Expressなど、シリアル伝送がより普及し、高速化していくというトレンドがあります。そのため、アルテラ社のCycloneのような低コストアプリケーション向けのFPGAにおいても、シリアルトランシーバ(SERDES)のサポートが当たり前のように要求されるようになってきました。
アルテラ社の場合、3つのFPGAファミリがターゲットとするアプリケーションの観点から、それぞれのファミリにおけるトランシーバのデータレートを次のように決めています。Stratix Vは最大28Gbpsと14.1Gbpsの2種類、Arria Vは最大10.3125Gbpsと6.375Gbpsの2種類、Cyclone Vは最大5Gbpsと3.125Gbpsの2種類です。
Copyright © ITmedia, Inc. All Rights Reserved.
Special Contents
- PR -
Special Contents
- PR -


Special Contents 1
- PR -


Special Contents 2
- PR -

Special Site
- PR -
Pickup Contents
- PR -

コーナーリンク
組み込み開発の記事ランキング
- Rapidusは新工場稼働間近、クエスト・グローバルとの協業でRUMSモデルが完成へ
- ROSのAIエージェント「RAI」を使って自然言語でアームロボットを制御する
- PLCのリアルタイム性を確保するために商用リアルタイムOSとライブラリを採用
- 日本の汎用ロボット開発の起爆剤となるか、基盤モデル構築目指すAIRoAが発足
- NVIDIAのGPUは「Blackwell Ultra」から「Rubin」へ、シリコンフォトニクスも採用
- CAN通信におけるデータ送信の仕組みとは?
- ロボットに生成AIを適用すると何ができるのか、課題は何なのか
- ウェアラブルエコーセンサーの共同プロジェクト、2026年の製品化を目指す
- Windows PCの製造業向けパッケージモデルに新オプション追加
- リアルタイムOS列伝まとめ(第31回~35回)
よく読まれている編集記者コラム



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。