バグは金曜日に生まれる?「MSR」最前線:5分でわかる最新キーワード解説
MSR(Mining Software Repositories)とはソースコードやドキュメントなど、開発に関して蓄積された情報を精査し、生産性や品質の向上に役立てようとする技術です。「バグが発生する日は金曜日」など気付かなかったコトが見えるようになります。
今回のテーマは「MSR(Mining Software Repositories)/ソフトウェアリポジトリマイニング」。ビッグデータ解析技術により、ソフトウェアの開発技術を変革する新しいトレンドが生まれようとしています。
MSR/ソフトウェアリポジトリマイニング」とは?
MSR(Mining Software Repositories)とは、ソフトウェアのソースコードやドキュメント、開発や運用・保守プロセスで発生した議論の記録など、ソフト開発に関連して蓄積された膨大な電子化情報の中から、新しいソフトの設計・開発・保守に利用可能な知見を抽出して活用し、ソフト開発の生産性・品質・保守性の向上を目指す新しい知識再利用技術を指します。
- MSRがマイニングする対象は?
「マイニング」(mining/採鉱)技術としてよく知られているのは「データマイニング」技術だろう。小売店の販売データを分析して「ビールを買う顧客が一緒に買う商品は紙おむつ」であるという一見不思議な相関関係が見つかったという有名なエピソードが語るように、業務データを見ているだけでは分からないデータ間の相関関係や傾向を導き出し、販売予測やマーケティングに役立てる分析技術のことだ。MSRも同様に、膨大に蓄積されたデータの中から役に立つ情報を取り出そうとする技術である。
ただし分析の対象とするデータの種類が違う。データマイニングが業務データを対象にするのに対しMSRはソフトウェアに関連するあらゆる情報を分析する。
図1に見るように、ソースコードはもちろんのこと、CVS(Concurrent Versions System/ファイルのバージョン管理システムのデータ)やSVN(Subversion/オープンソースのバージョン管理ツールのデータ)、バグ報告(バグトラッキングシステムのデータやその他の資料)、クラッシュログ、実行履歴、メール(SNSやブログ、掲示板なども含む場合がある)などがマイニングの対象だ。それらのデータは構造化されてデータベースに格納されているものもあれば、文書やテキストなどの非構造化データとして蓄積されている。共通点は電子化されているということだけかもしれない。それらを一元的に「リポジトリ」といういわば貯蔵庫に入れて、さまざまなアルゴリズムを駆使して分析するのがMSRの方法だ。
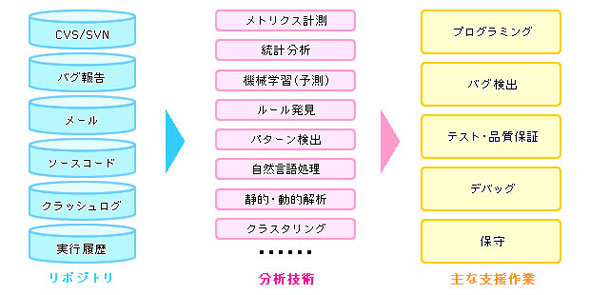 図1 「MSR」の概要 資料提供:ソフトウェアジャパン2013、ITフォーラムセッション「ソフトウェアリポジトリマイニングの技術動向とその応用」(奈良先端科学技術大学院大学 門田暁人)より
図1 「MSR」の概要 資料提供:ソフトウェアジャパン2013、ITフォーラムセッション「ソフトウェアリポジトリマイニングの技術動向とその応用」(奈良先端科学技術大学院大学 門田暁人)より- MSRが改めて注目される背景
MSRは実証的ソフトウェア工学(Empirical Software Engineering)の1つのアプローチとして、十数年前からアカデミズムの世界で研究されてきた。それが今あらためて注目されるのは、コンピューティング能力の指数関数的な増大とともにソフトウェアに関連する電子化情報が爆発的に増大してビッグデータ化していることが背景にある。例えば今回取材したNTTデータでは、直近7年間で300Mステップに及ぶソースコードが蓄積されているといい、あるプロジェクトでは開発関連ドキュメントが数千万ファイルにものぼる。これに加え、Web上には少なくとも1億ページ以上の技術情報ページがあり、数千万ファイルのオープンソースのコードが存在するといわれている。
構造化データと非構造化データが混在する多様なデータが日々生まれては蓄積されていく中で、一方ではビッグデータ分析技術も近年急速に成熟してきた。例えばコード解析、データマイニング、テキストマイニング、統計解析、パターンマッチング、自然言語処理、ソーシャルネットワーク分析、機械学習などといった技術により、従来はITが扱い切れなかった量と種類のデータが、今のところそれぞれ限界はあるにしても、全てが分析可能になってきた。今こそ、開発資産のマイニングが現実的なメリットを生むのではないかという期待が高まっているのだ。
- MSRでどんなことができるのか?
では、MSRはそんな期待にどう答えるのだろうか。以下に代表的な応用例を挙げてみよう。
- ソフト資産の再利用の支援:資産カタログの生成
開発生産性や品質向上に直接寄与する応用の1つは、開発資産のカタログ化だ。従来、開発資産を再利用するためには、例えば「サブルーチン」や「クラスライブラリ」のように機能を切り分けて、目的のソフト開発だけでなく同じような処理を必要とする他のソフトに組み込めるようにしたり、「フレームワーク」のようにさらに大きな単位での機能をひとまとめにしたりする手法が使われてきた。
しかし、実際には特定業務目的の機能が他の目的のソフトにそのまま適用できる場合は限られている。またどれが再利用に適するのか、修正すべきところはどこかを見分けるのにも大きな手間がかかる。あらかじめ再利用可能なソフトウェア部品として作成することも、理論的には可能とはいえ、現実的なソフト開発スケジュールの中で行うのには困難が伴っていた。
そこで膨大で多種にわたる開発資産の中から、自動的に再利用可能な資産を抽出し、再利用しやすい形に構成し直してくれる仕組みがあるとよい。MSRの研究は、そんな「資産カタログの自動生成」も対象としている。既にNTTデータでの実証例があり、同社のあるプロジェクトでは再利用設計期間の84%削減、開発全体で8%の工期短縮に結びついたという。
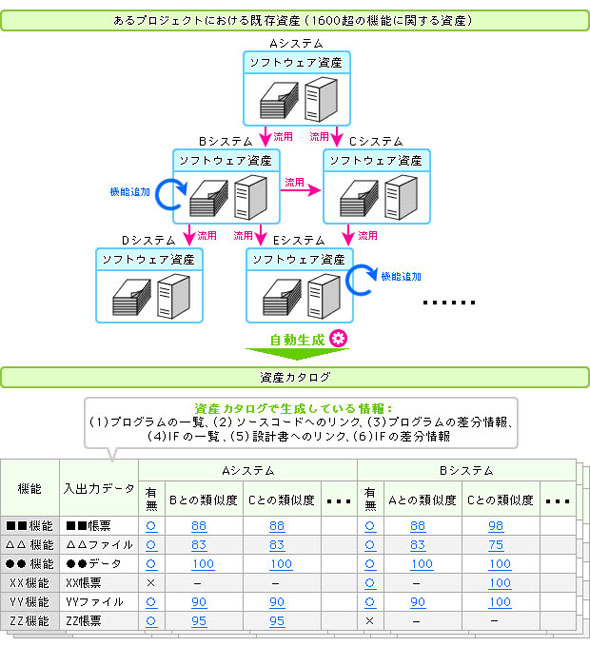 図2 「MSR」による「資産カタログ」の生成(資料提供:NTTデータ)
図2 「MSR」による「資産カタログ」の生成(資料提供:NTTデータ)MSRが直接再利用可能な「部品」を生成してくれるわけではないが、どのような場合に何が再利用できるのかのリストを作成し、類似度を見て修正が必要な度合いや場所が迅速に把握できるので、新しいシステムの追加や既存システムの一部改修に際して都度既存資産を解析し直すことなく、再利用設計が行えることになる。
いわば、機械によってソースコードを自動的にライブラリ化し、開発担当者が流用するのに適切な部品をレコメンドしてくれるというイメージだ。開発の意思決定におおいに役立つとともに、部品流用により開発生産性、品質、保守性も大きく改善できそうだ。
- 評価・予測の支援:バグモジュール予測
開発資産の中から傾向を見つけ出し、評価や予測に結び付けることにも期待が寄せられている。実用化に近いのは、開発したソフトに含まれるモジュールにバグが含まれる可能性の予測技術だ。例えばGoogleの「バグ予測アルゴリズム」(ソースコードの修正履歴をもとにしたバグ予測を行う技術)のような研究が、各国企業や研究機関で進められている。
イメージとしては図3に見るように、ソースコードやバグ情報、関連情報を分析し、どのモジュール、どのコードのどの個所にバグが含まれる可能性が高いかを予測するものだ。それがわかれば、バグを含む可能性が高いモジュールに重点的にテストして品質向上に結び付けられそうだ。また評価やテストの工程全体を短縮することもできるかもしれない。
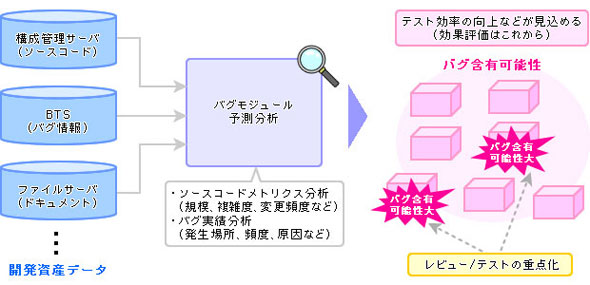 図3 「MSR」によるバグモジュールの予測分析(資料提供:NTTデータ)
図3 「MSR」によるバグモジュールの予測分析(資料提供:NTTデータ)コラム:バグ修正のための変更の4割が新たなバグに!
MSR研究の面白い成果の例を紹介しよう。アメリカの研究グループによる研究によると、次のような事実が分かった(電話交換機のサブシステム:200万行のコード、3万3000件の変更仕様を対象に調査)。
1. 不具合修正のための変更の40%が新たなバグを混入している(デグレード)
2. 1行追加の差分では2%、1行変更の差分では5%程度がバグを混入している
3. 500行以上の変更でバグを混入する可能性は50%
またドイツの研究グループはEclipseとMozillaプロジェクトのバグトラッキングデータから、「最もバグ発生の頻度の高いのは週のうち金曜日」という興味深い事実を導き出してもいる。
だからどんな対応が必要なのか、というのはまた別の話だが、「ビールとおむつ」のエピソードと同様に今まで見ようとしても見えなかった事実、または仮説を立てようともしなかった発想での真実が明らかになることが分かる。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- 5G通信の遅延時間1ms以下は複数端末の制御でも可能か、東芝が量子技術で道を開く
- CAN通信におけるデータ送信の仕組みとは?
- イチから全部作ってみよう(7)正しい要求仕様書の第一歩となるヒアリングの手順
- CANプロトコルを理解するための基礎知識
- 組み込みシステム向けRTOSのシェアはTRON系が約60%
- ソニーのLPWA「ELTRES」の通信モジュールが機能追加、システムの簡素化が可能に
- インフィニオンのSiC-MOSFETは第2世代へ、質も量も圧倒
- 【問題7】10進数を2進数に変換するプログラム
- テスト消化曲線とバグ発生曲線の7パターン診断
- 6Gに向けたサブテラヘルツ帯対応無線デバイス、100Gbpsの超高速伝送を実証
よく読まれている編集記者コラム



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。