人工知能の新技術で、文字の認識ミスを従来の半分以下に:人工知能ニュース
富士通研究所と富士通研究開発中心は、手書き文字列での画像認識において、信頼性の高い認識結果を出力する人工知能モデルを開発した。文字列中の区切りも効果的に判別でき、文字の認識ミスを従来の半分以下に抑える。
富士通研究所と、中国北京を本拠地とする富士通研究開発中心は2016年11月8日、手書き文字列での画像認識で、信頼性の高い認識結果を出力する人工知能モデルを開発したと発表した。
従来の人工知能モデルによる中国語の文字認識は、手書きの文字列に適用すると、文字の区切りを正しく判別できないことが課題となっていた。
両社は、中国語文中で隣り合って現れやすいパーツの組み合わせを「非文字」(部首やつくり、またそれらを組み合わせても文字にならないもの)とし、その教師サンプルを作成。これを従来の文字の教師サンプルに加えて異種深層学習モデルとした。
また、学習済みの異種深層学習モデルに対し、正しい文字の候補領域には高い信頼度、文字ではない候補領域には低い信頼度を出力する仕組みを設定。文字列中の文字の区切りを効果的に判別する技術を開発した。これにより、正しい文字のみに高い信頼度が出力され、文字の認識ミスを従来の半分以下に抑止できるようになった。
さらに、既存の中国語言語処理モデルを適用して、認識候補が正しい中国語の文字列になるか否かを解析し、候補文章を出力する。
同技術は、単語の区切りにスペースを用いない中国語や日本語、韓国語などの言語に対して有効だ。また、これを富士通研究所の日本語言語処理技術と融合することで、日本語の手書き文字においても認識精度の向上が期待できる。
2017年には、同技術を富士通のAI技術「Zinrai」に活用し、日本向けの手書き帳票電子化などのソリューションに順次適用していく。
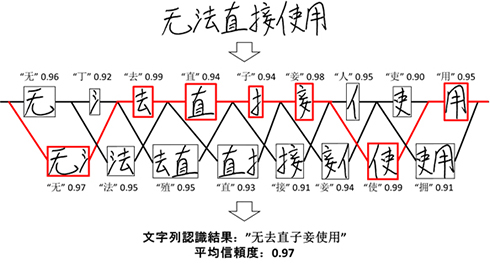 従来深層学習モデルの文字列認識結果
従来深層学習モデルの文字列認識結果

関連記事
 人工知能は製造現場でどう役に立つのか
人工知能は製造現場でどう役に立つのか
人間の知的活動を代替するといわれる人工知能が大きな注目を集めている。ただ、製造現場で「使える」人工知能は、一般的に言われているような大規模演算が必要なものではない。「使える人工知能」に向けていち早く実現へと踏み出しているファナックとPFNの取り組みを紹介する。 第4次産業革命って結局何なの?
第4次産業革命って結局何なの?
製造業の産業構造を大きく変えるといわれている「第4次産業革命」。しかし、そこで語られることは抽象的で、いまいちピンと来ません。本連載では、そうした疑問を解消するため、第4次産業革命で起こることや、必要となることについて分かりやすくお伝えするつもりです。第1回目はそもそもの「第4次産業革命とは何か」を紹介します。 製造業IoTに新たなデファクト誕生か、ファナックらが人工知能搭載の情報基盤開発へ
製造業IoTに新たなデファクト誕生か、ファナックらが人工知能搭載の情報基盤開発へ
ファナックやシスコシステムズら4社は、製造現場向けのIoTプラットフォームとして「FIELD system」を開発し、2016年度中にリリースすることを発表した。競合メーカーの製品なども接続可能なオープンな基盤とする方針。製造業IoTでは各種団体が取り組むが、ファナックでは既に製造現場に350万台以上の機器を出荷している強みを生かし「現場発」の価値を訴求する。 熟練技術者のスキルを8時間で獲得、ファナックが機械学習ロボットを披露
熟練技術者のスキルを8時間で獲得、ファナックが機械学習ロボットを披露
ファナックは「2015 国際ロボット展」で、Preferred Networks(PFN)と提携して開発している産業用ロボットへの機械学習の適用事例を披露した。機械学習により熟練技術者が数日間かかるティーチングの精度を、8時間で実現したという。 製造業で人工知能はどう使うべきなのか
製造業で人工知能はどう使うべきなのか
日本IBMとソフトバンクは、自然対話型人工知能「ワトソン(Watson)」の日本語版の提供を開始する。自然言語分類や対話、検索およびランク付け、文書変換など6つのアプリケーションをサービスとして展開する。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
よく読まれている編集記者コラム



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。