
AIと機械学習とディープラーニングは何が違うのか:いまさら聞けない機械学習入門(前編)(2/3 ページ)
5.「教師あり学習」と「教師なし学習」
機械学習でできることは何だろうか。機械学習の方法は、大きく分けると入力データに対する回答を与えることで学習できる「教師あり学習」と、回答を与えずに学習する「教師なし学習」がある。
教師あり学習では、変動する実数値の予測である回帰と、2つ以上の項目への分類の2種類の予測が可能だ。実数値の変動とは、例えば摩耗するパッドの残りの厚さや、ポンプ装置の故障までの日数などが相当する。分類では迷惑メールか否か、故障の種類や画像認識による個人の判別などが当てはまる。世間で目立つのは分類のほうだが、製造業では意外と回帰が役に立つことが多い。教師なし学習ではグループ化をしてデータの分析を行うことができる。なお、現在よく使われている手法は教師あり学習の方だ。
教師あり学習について整理してみよう。まずはゴールとなる目的変数を定める。ここでは例として「今月の作業ミスの件数」としよう。実数値が対象なので回帰となる。入力となる説明変数に何を入れるのかは、この予測モデルの設計者が決める。ここでは室内の温度、湿度、作業は何月か、偉い人のご機嫌、自分が投資している株価、お昼ご飯の種類といった変数を入れてみることにする。これらの説明変数のどれがどのくらい目的変数に相関があるかは、誰にも分からないブラックボックスといえるだろう。
そこで、説明変数と対応する目的変数の組み合わせを大量に用意し、コンピュータにブラックボックス内の仕組みを推察させる。推察した仕組みは予測モデルとなり、新たな説明変数のデータを入力することで、未知の目的変数の値を算出できるようになる(図2)。

とはいえ、機械学習はどんな問題にも適用できる万能の魔法ではない。以下の5つの条件を満たした問題であれば、適用できる可能性が高い。
- ゴールとなる結果やイベントが数字として定義できる
- 結果やイベントの発生回数が十分にある
- ゴールに関係する、説明変数のデータが入手できる
- 十分な量の過去のデータを利用できる
- データから「学習」できる、つまり良質な学習アルゴリズムがある
1は当然としても、2の発生回数や4の過去データの量はどのくらい必要なのか、というのは対象となる問題によるので一概には言えない。また3についても、説明変数がゴールに関係しているかどうかは予測モデルを作成して検証するまでは分からない。従って、まず手持ちのデータで手早く予測モデルを作成し、検証をしてから方針を修正していく必要がある。取り組む前に悩むよりも、手を動かしてまずやってみることが大事だ。
6.機械学習に使われるアルゴリズム
機械学習に使われるアルゴリズムは多岐にわたるため、ここでは代表的なものを幾つか列挙する。一番イメージしやすいのは「線形回帰」だろう。多数のデータプロットから最も誤差が少ない直線を引けるようにパラメーターを調整する(図3)。
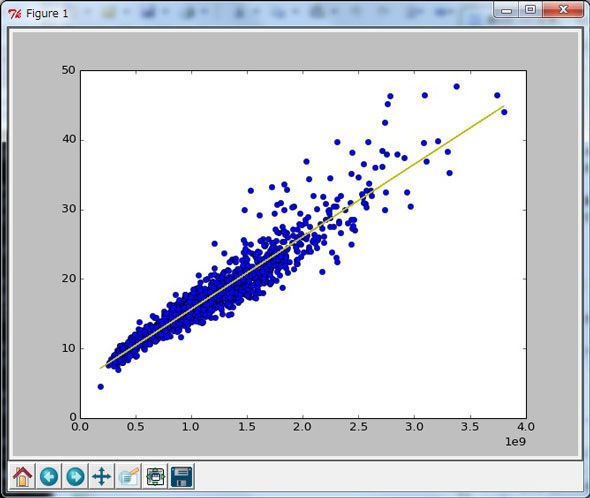 図3 線形回帰の事例 出典:
図3 線形回帰の事例 出典:最も適切に2種類の分類ができるように曲線のパラメーターを調整するのが「ロジスティック回帰」。条件により二つの枝分かれを繰り返すのが「決定木」(図4)。そして、最近の流行として「ニューラルネットワーク」がある。
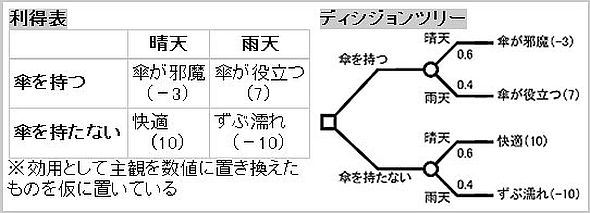 図4 “傘を持つか持たないか”という決定問題を示す利得表(左)と決定木(右) 出典:
図4 “傘を持つか持たないか”という決定問題を示す利得表(左)と決定木(右) 出典:ニューラルネットワークとは、人間の脳の神経細胞にヒントを得て数理モデル化したアルゴリズムだ。ニューロンと呼ばれるモデルに、複数の変数を入力して所定の計算結果を出力する仕組みを作る。このモデルを複数並べて接続したものを層として取りまとめ隠れ層とする。最後の層は出力層とし、最終的な結果を得られるようにする。
このニューラルネットにより、今までコンピュータがあまりうまく扱えなかった、画像や音声の分類ができるようになったといわれている。ただし注意して欲しいのは、人間の脳の働きを模しているわけではないことだ。あくまで参考にしただけである。

Copyright © ITmedia, Inc. All Rights Reserved.
組み込み開発の記事ランキング
- 低価格FPGAでも文字認識AIの学習は可能なのか
- インフィニオンのSiC-MOSFETは第2世代へ、質も量も圧倒
- 組み込みシステム向けRTOSのシェアはTRON系が約60%
- パナソニックの電動アシスト自転車にエッジAI機能を提供
- スバルが次世代「EyeSight」に採用、AMDの第2世代「Versal AI Edge」
- イチから全部作ってみよう(7)正しい要求仕様書の第一歩となるヒアリングの手順
- CAN通信におけるデータ送信の仕組みとは?
- 自社開発のRISC-V CPUコアを搭載した32ビット汎用マイコン
- 東武ストアが指静脈による手ぶら決済を開始、酒類対応でセルフレジ利用率60%も
- CANプロトコルを理解するための基礎知識
よく読まれている編集記者コラム



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。